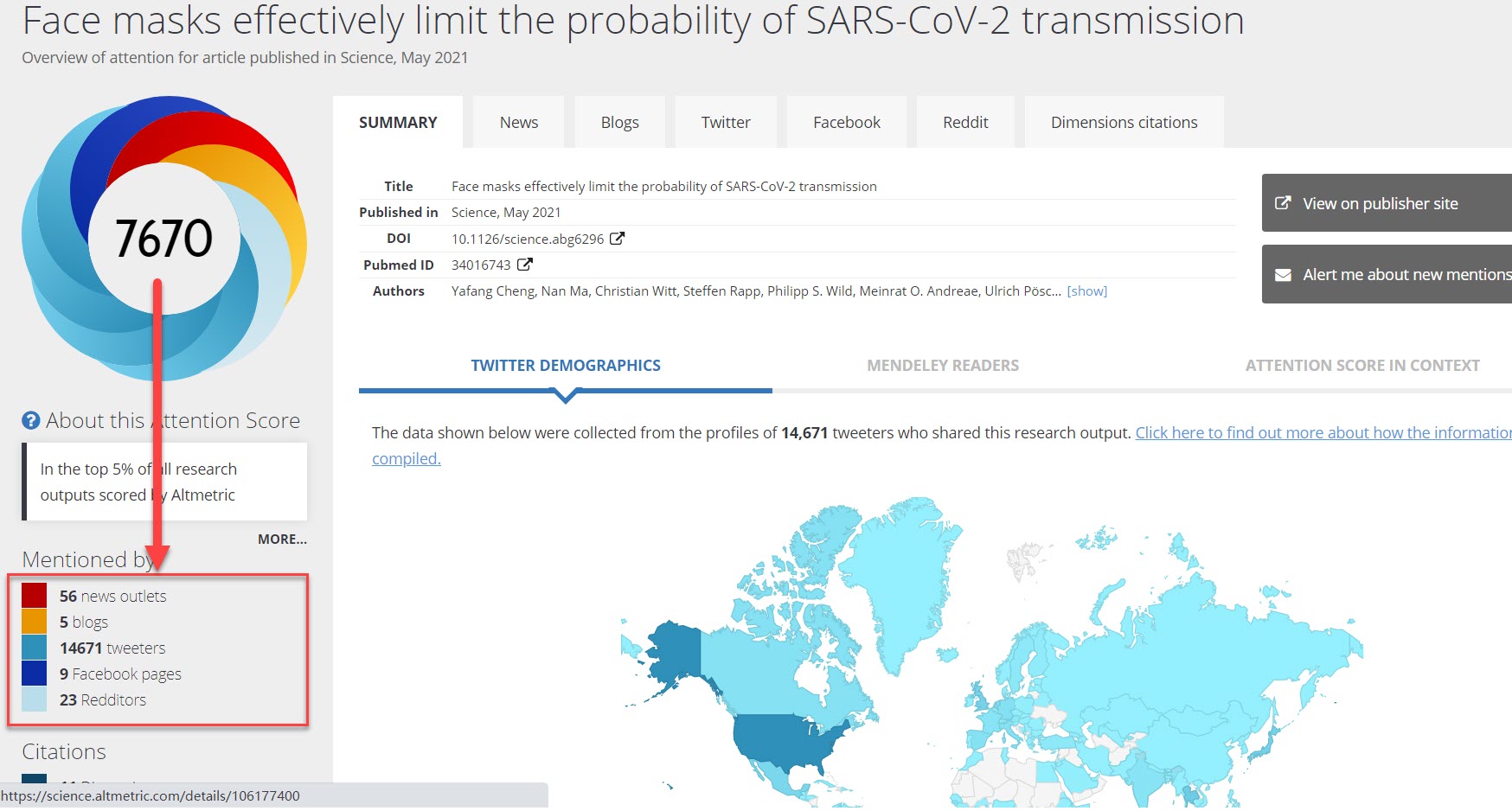
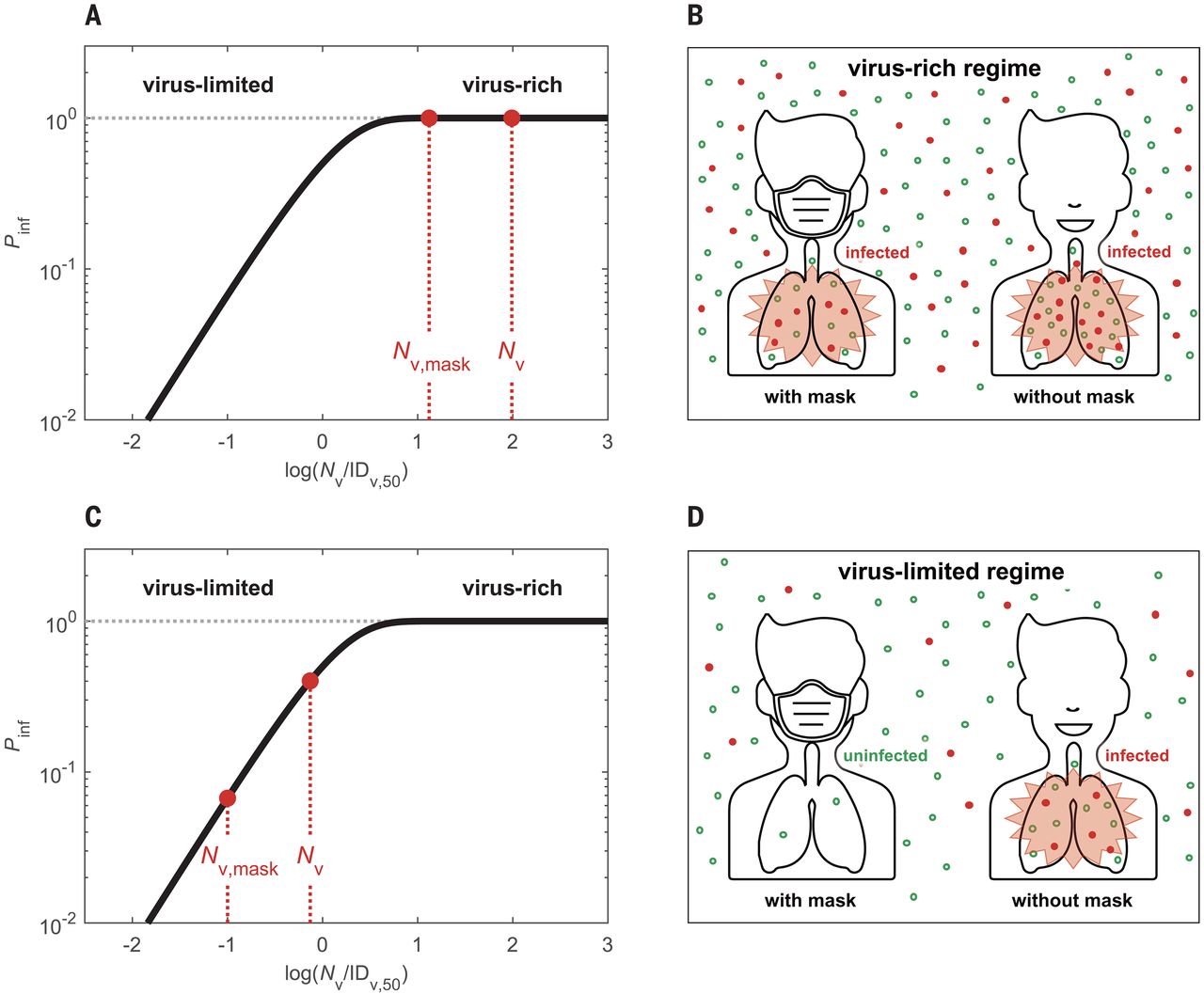
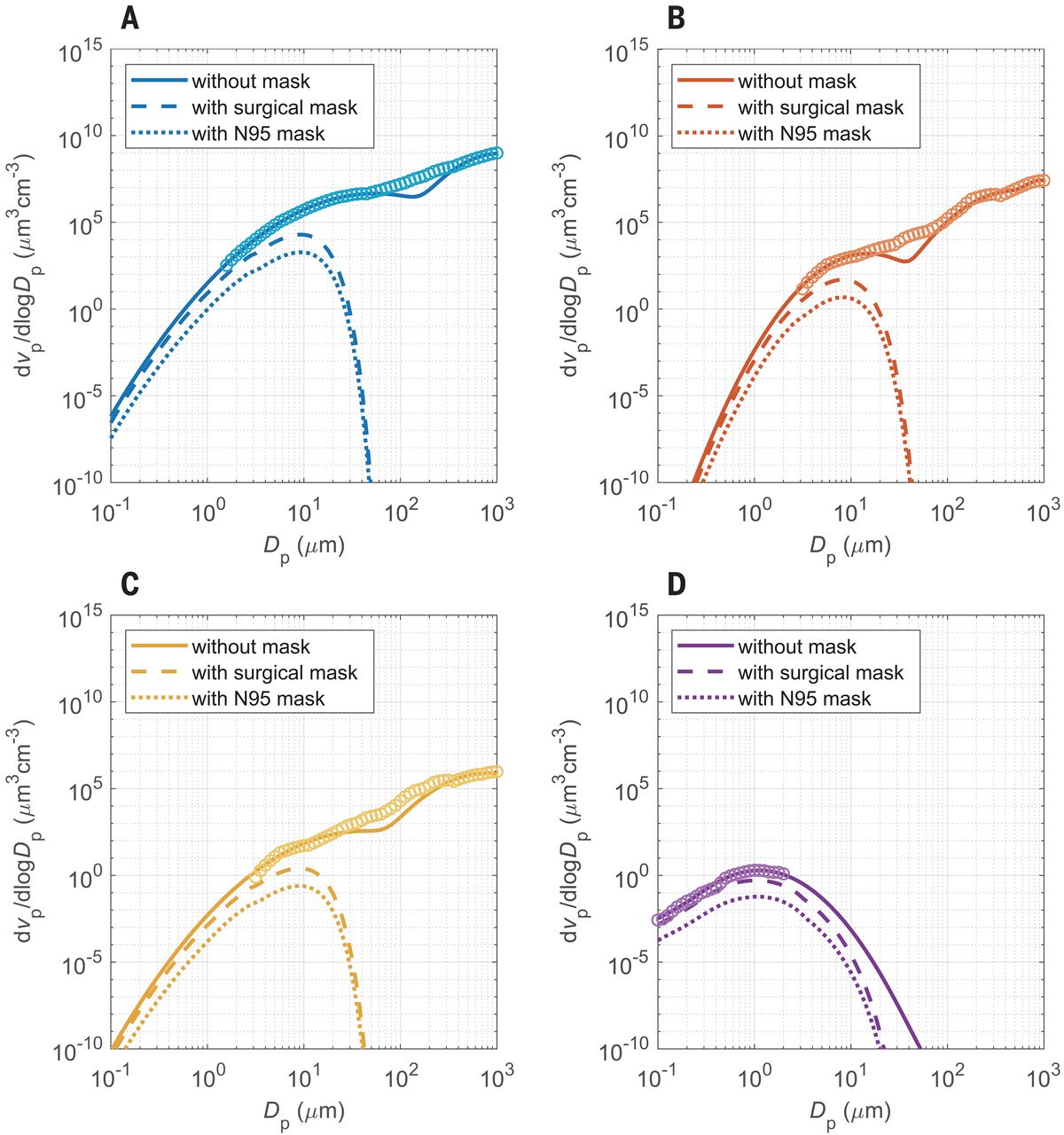
Last Updated on August 15, 2020
You need standard datasets to practice machine learning.
In this short post you will discover how you can load standard classification and regression datasets in R.
This post will show you 3 R libraries that you can use to load standard datasets and 10 specific datasets that you can use for machine learning in R.
It is invaluable to load standard datasets in R so that you can test, practice and experiment with machine learning techniques and improve your skill with the platform.
Kick-start your project with my new book Machine Learning Mastery With R, including step-by-step tutorials and the R source code files for all examples.
Let’s get started.
Practice On Small Well-Understood Datasets
There are hundreds of standard test datasets that you can use to practice and get better at machine learning.
Most of them are hosted for free on the UCI Machine Learning Repository. These datasets are useful because they are well understood, they are well behaved and they are small.
This last point is critical when practicing machine learning because:
- You can download them fast.
- You can fit them into memory easily.
- You can run algorithms on them quickly.
Learn more about practicing machine learning using datasets from the UCI Machine Learning Repository in the post:
Access Standard Datasets in R
You can load the standard datasets into R as CSV files.
There is a more convenient approach to loading the standard dataset. They have been packaged and are available in third party R libraries that you can download from the Comprehensive R Archive Network (CRAN).
Which libraries should you use and what datasets are good to start with.
Need more Help with R for Machine Learning?
Take my free 14-day email course and discover how to use R on your project (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
https://machinelearningmastery.lpages.co/leadbox/141caac73f72a2%3A164f8be4f346dc/5734055144325120/" data-leadbox-id="141caac73f72a2:164f8be4f346dc">Start Your FREE Mini-Course Now!
How To Load Standard Datasets in R
In this section you will discover the libraries that you can use to get access to standard machine learning datasets.
You will also discover specific classification and regression that you can load and use to practice machine learning in R.
Library: datasets
Iris Flowers Dataset
Photo by Rick Ligthelm, some rights reserved.
The datasets library comes with base R which means you do not need to explicitly load the library. It includes a large number of datasets that you can use.
You can load a dataset from this library by typing:
|
1
|
data(DataSetName)
|
For example, to load the very commonly used iris dataset:
|
1
|
data(iris)
|
To see a list of the datasets available in this library, you can type:
|
1
2
|
# list all datasets in the package
library(help = "datasets")
|
Some highlights datasets from this package that you could use are below.
Iris Flowers Dataset
- Description: Predict iris flower species from flower measurements.
- Type: Multi-class classification
- Dimensions: 150 instances, 5 attributes
- Inputs: Numeric
- Output: Categorical, 3 class labels
- UCI Machine Learning Repository: Description
- Published accuracy results: Summary
|
1
2
3
4
5
|
# iris flowers datasets
data(iris)
dim(iris)
levels(iris$Species)
head(iris)
|
You will see:
|
1
2
3
4
5
6
7
|
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
|
Longley’s Economic Regression Data
- Description: Predict number of people employed from economic variables
- Type: Regression
- Dimensions: 16 instances, 7 attributes
- Inputs: Numeric
- Output: Numeric
|
1
2
3
4
|
# Longley's Economic Regression Data
data(longley)
dim(longley)
head(longley)
|
You will see:
|
1
2
3
4
5
6
7
|
GNP.deflator GNP Unemployed Armed.Forces Population Year Employed
1947 83.0 234.289 235.6 159.0 107.608 1947 60.323
1948 88.5 259.426 232.5 145.6 108.632 1948 61.122
1949 88.2 258.054 368.2 161.6 109.773 1949 60.171
1950 89.5 284.599 335.1 165.0 110.929 1950 61.187
1951 96.2 328.975 209.9 309.9 112.075 1951 63.221
1952 98.1 346.999 193.2 359.4 113.270 1952 63.639
|
Library: mlbench
Soybean Dataset
Photo by United Soybean Board, some rights reserved.
Direct from the manual for the library:
A collection of artificial and real-world machine learning benchmark problems, including, e.g., several data sets from the UCI repository.
You can learn more about the mlbench library on the mlbench CRAN page.
If not installed, you can install this library as follows:
|
1
|
install.packages("mlbench")
|
You can load the library as follows:
|
1
2
|
# load the library
library(mlbench)
|
To see a list of the datasets available in this library, you can type:
|
1
2
|
# list the contents of the library
library(help = "mlbench")
|
Some highlights datasets from this library that you could use are:
Boston Housing Data
- Description: Predict the house price in Boston from house details
- Type: Regression
- Dimensions: 506 instances, 14 attributes
- Inputs: Numeric
- Output: Numeric
- UCI Machine Learning Repository: Description
|
1
2
3
4
|
# Boston Housing Data
data(BostonHousing)
dim(BostonHousing)
head(BostonHousing)
|
You will see:
|
1
2
3
4
5
6
7
|
crim zn indus chas nox rm age dis rad tax ptratio b lstat medv
1 0.00632 18 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98 24.0
2 0.02731 0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14 21.6
3 0.02729 0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03 34.7
4 0.03237 0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94 33.4
5 0.06905 0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7 396.90 5.33 36.2
6 0.02985 0 2.18 0 0.458 6.430 58.7 6.0622 3 222 18.7 394.12 5.21 28.7
|
Wisconsin Breast Cancer Database
- Description: Predict whether a cancer is malignant or benign from biopsy details.
- Type: Binary Classification
Dimensions: 699 instances, 11 attributes - Inputs: Integer (Nominal)
- Output: Categorical, 2 class labels
- UCI Machine Learning Repository: Description
- Published accuracy results: Summary
|
1
2
3
4
5
|
# Wisconsin Breast Cancer Database
data(BreastCancer)
dim(BreastCancer)
levels(BreastCancer$Class)
head(BreastCancer)
|
You will see:
|
1
2
3
4
5
6
7
|
Id Cl.thickness Cell.size Cell.shape Marg.adhesion Epith.c.size Bare.nuclei Bl.cromatin Normal.nucleoli Mitoses Class
1 1000025 5 1 1 1 2 1 3 1 1 benign
2 1002945 5 4 4 5 7 10 3 2 1 benign
3 1015425 3 1 1 1 2 2 3 1 1 benign
4 1016277 6 8 8 1 3 4 3 7 1 benign
5 1017023 4 1 1 3 2 1 3 1 1 benign
6 1017122 8 10 10 8 7 10 9 7 1 malignant
|
Glass Identification Database
- Description: Predict the glass type from chemical properties.
- Type: Classification
- Dimensions: 214 instances, 10 attributes
- Inputs: Numeric
- Output: Categorical, 7 class labels
- UCI Machine Learning Repository: Description
- Published accuracy results: Summary
|
1
2
3
4
5
|
# Glass Identification Database
data(Glass)
dim(Glass)
levels(Glass$Type)
head(Glass)
|
You will see:
|
1
2
3
4
5
6
7
|
RI Na Mg Al Si K Ca Ba Fe Type
1 1.52101 13.64 4.49 1.10 71.78 0.06 8.75 0 0.00 1
2 1.51761 13.89 3.60 1.36 72.73 0.48 7.83 0 0.00 1
3 1.51618 13.53 3.55 1.54 72.99 0.39 7.78 0 0.00 1
4 1.51766 13.21 3.69 1.29 72.61 0.57 8.22 0 0.00 1
5 1.51742 13.27 3.62 1.24 73.08 0.55 8.07 0 0.00 1
6 1.51596 12.79 3.61 1.62 72.97 0.64 8.07 0 0.26 1
|
Johns Hopkins University Ionosphere database
- Description: Predict high-energy structures in the atmosphere from antenna data.
- Type: Classification
- Dimensions: 351 instances, 35 attributes
- Inputs: Numeric
- Output: Categorical, 2 class labels
- UCI Machine Learning Repository: Description
- Published accuracy results: Summary
|
1
2
3
4
5
|
# Johns Hopkins University Ionosphere database
data(Ionosphere)
dim(Ionosphere)
levels(Ionosphere$Class)
head(Ionosphere)
|
You will see:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14 V15 V16 V17 V18 V19
1 1 0 0.99539 -0.05889 0.85243 0.02306 0.83398 -0.37708 1.00000 0.03760 0.85243 -0.17755 0.59755 -0.44945 0.60536 -0.38223 0.84356 -0.38542 0.58212
2 1 0 1.00000 -0.18829 0.93035 -0.36156 -0.10868 -0.93597 1.00000 -0.04549 0.50874 -0.67743 0.34432 -0.69707 -0.51685 -0.97515 0.05499 -0.62237 0.33109
3 1 0 1.00000 -0.03365 1.00000 0.00485 1.00000 -0.12062 0.88965 0.01198 0.73082 0.05346 0.85443 0.00827 0.54591 0.00299 0.83775 -0.13644 0.75535
4 1 0 1.00000 -0.45161 1.00000 1.00000 0.71216 -1.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 -1.00000 0.14516 0.54094 -0.39330 -1.00000
5 1 0 1.00000 -0.02401 0.94140 0.06531 0.92106 -0.23255 0.77152 -0.16399 0.52798 -0.20275 0.56409 -0.00712 0.34395 -0.27457 0.52940 -0.21780 0.45107
6 1 0 0.02337 -0.00592 -0.09924 -0.11949 -0.00763 -0.11824 0.14706 0.06637 0.03786 -0.06302 0.00000 0.00000 -0.04572 -0.15540 -0.00343 -0.10196 -0.11575
V20 V21 V22 V23 V24 V25 V26 V27 V28 V29 V30 V31 V32 V33 V34 Class
1 -0.32192 0.56971 -0.29674 0.36946 -0.47357 0.56811 -0.51171 0.41078 -0.46168 0.21266 -0.34090 0.42267 -0.54487 0.18641 -0.45300 good
2 -1.00000 -0.13151 -0.45300 -0.18056 -0.35734 -0.20332 -0.26569 -0.20468 -0.18401 -0.19040 -0.11593 -0.16626 -0.06288 -0.13738 -0.02447 bad
3 -0.08540 0.70887 -0.27502 0.43385 -0.12062 0.57528 -0.40220 0.58984 -0.22145 0.43100 -0.17365 0.60436 -0.24180 0.56045 -0.38238 good
4 -0.54467 -0.69975 1.00000 0.00000 0.00000 1.00000 0.90695 0.51613 1.00000 1.00000 -0.20099 0.25682 1.00000 -0.32382 1.00000 bad
5 -0.17813 0.05982 -0.35575 0.02309 -0.52879 0.03286 -0.65158 0.13290 -0.53206 0.02431 -0.62197 -0.05707 -0.59573 -0.04608 -0.65697 good
6 -0.05414 0.01838 0.03669 0.01519 0.00888 0.03513 -0.01535 -0.03240 0.09223 -0.07859 0.00732 0.00000 0.00000 -0.00039 0.12011 bad
|
Pima Indians Diabetes Database
- Description: Predict the onset of diabetes in female Pima Indians from medical record data.
- Type: Binary Classification
- Dimensions: 768 instances, 9 attributes
- Inputs: Numeric
- Output: Categorical, 2 class labels
- Dataset Details: Description
- Published accuracy results: Summary
|
1
2
3
4
5
|
# Pima Indians Diabetes Database
data(PimaIndiansDiabetes)
dim(PimaIndiansDiabetes)
levels(PimaIndiansDiabetes$diabetes)
head(PimaIndiansDiabetes)
|
You will see:
|
1
2
3
4
5
6
7
|
pregnant glucose pressure triceps insulin mass pedigree age diabetes
1 6 148 72 35 0 33.6 0.627 50 pos
2 1 85 66 29 0 26.6 0.351 31 neg
3 8 183 64 0 0 23.3 0.672 32 pos
4 1 89 66 23 94 28.1 0.167 21 neg
5 0 137 40 35 168 43.1 2.288 33 pos
6 5 116 74 0 0 25.6 0.201 30 neg
|
Sonar, Mines vs. Rocks
- Description: Predict metal or rock returns from sonar return data.
- Type: Binary Classification
- Dimensions: 208 instances, 61 attributes
- Inputs: Numeric
- Output: Categorical, 2 class labels
- UCI Machine Learning Repository: Description
- Published accuracy results: Summary
|
1
2
3
4
5
|
# Sonar, Mines vs. Rocks
data(Sonar)
dim(Sonar)
levels(Sonar$Class)
head(Sonar)
|
You will see:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14 V15 V16 V17 V18 V19 V20 V21 V22
1 0.0200 0.0371 0.0428 0.0207 0.0954 0.0986 0.1539 0.1601 0.3109 0.2111 0.1609 0.1582 0.2238 0.0645 0.0660 0.2273 0.3100 0.2999 0.5078 0.4797 0.5783 0.5071
2 0.0453 0.0523 0.0843 0.0689 0.1183 0.2583 0.2156 0.3481 0.3337 0.2872 0.4918 0.6552 0.6919 0.7797 0.7464 0.9444 1.0000 0.8874 0.8024 0.7818 0.5212 0.4052
3 0.0262 0.0582 0.1099 0.1083 0.0974 0.2280 0.2431 0.3771 0.5598 0.6194 0.6333 0.7060 0.5544 0.5320 0.6479 0.6931 0.6759 0.7551 0.8929 0.8619 0.7974 0.6737
4 0.0100 0.0171 0.0623 0.0205 0.0205 0.0368 0.1098 0.1276 0.0598 0.1264 0.0881 0.1992 0.0184 0.2261 0.1729 0.2131 0.0693 0.2281 0.4060 0.3973 0.2741 0.3690
5 0.0762 0.0666 0.0481 0.0394 0.0590 0.0649 0.1209 0.2467 0.3564 0.4459 0.4152 0.3952 0.4256 0.4135 0.4528 0.5326 0.7306 0.6193 0.2032 0.4636 0.4148 0.4292
6 0.0286 0.0453 0.0277 0.0174 0.0384 0.0990 0.1201 0.1833 0.2105 0.3039 0.2988 0.4250 0.6343 0.8198 1.0000 0.9988 0.9508 0.9025 0.7234 0.5122 0.2074 0.3985
V23 V24 V25 V26 V27 V28 V29 V30 V31 V32 V33 V34 V35 V36 V37 V38 V39 V40 V41 V42 V43 V44
1 0.4328 0.5550 0.6711 0.6415 0.7104 0.8080 0.6791 0.3857 0.1307 0.2604 0.5121 0.7547 0.8537 0.8507 0.6692 0.6097 0.4943 0.2744 0.0510 0.2834 0.2825 0.4256
2 0.3957 0.3914 0.3250 0.3200 0.3271 0.2767 0.4423 0.2028 0.3788 0.2947 0.1984 0.2341 0.1306 0.4182 0.3835 0.1057 0.1840 0.1970 0.1674 0.0583 0.1401 0.1628
3 0.4293 0.3648 0.5331 0.2413 0.5070 0.8533 0.6036 0.8514 0.8512 0.5045 0.1862 0.2709 0.4232 0.3043 0.6116 0.6756 0.5375 0.4719 0.4647 0.2587 0.2129 0.2222
4 0.5556 0.4846 0.3140 0.5334 0.5256 0.2520 0.2090 0.3559 0.6260 0.7340 0.6120 0.3497 0.3953 0.3012 0.5408 0.8814 0.9857 0.9167 0.6121 0.5006 0.3210 0.3202
5 0.5730 0.5399 0.3161 0.2285 0.6995 1.0000 0.7262 0.4724 0.5103 0.5459 0.2881 0.0981 0.1951 0.4181 0.4604 0.3217 0.2828 0.2430 0.1979 0.2444 0.1847 0.0841
6 0.5890 0.2872 0.2043 0.5782 0.5389 0.3750 0.3411 0.5067 0.5580 0.4778 0.3299 0.2198 0.1407 0.2856 0.3807 0.4158 0.4054 0.3296 0.2707 0.2650 0.0723 0.1238
V45 V46 V47 V48 V49 V50 V51 V52 V53 V54 V55 V56 V57 V58 V59 V60 Class
1 0.2641 0.1386 0.1051 0.1343 0.0383 0.0324 0.0232 0.0027 0.0065 0.0159 0.0072 0.0167 0.0180 0.0084 0.0090 0.0032 R
2 0.0621 0.0203 0.0530 0.0742 0.0409 0.0061 0.0125 0.0084 0.0089 0.0048 0.0094 0.0191 0.0140 0.0049 0.0052 0.0044 R
3 0.2111 0.0176 0.1348 0.0744 0.0130 0.0106 0.0033 0.0232 0.0166 0.0095 0.0180 0.0244 0.0316 0.0164 0.0095 0.0078 R
4 0.4295 0.3654 0.2655 0.1576 0.0681 0.0294 0.0241 0.0121 0.0036 0.0150 0.0085 0.0073 0.0050 0.0044 0.0040 0.0117 R
5 0.0692 0.0528 0.0357 0.0085 0.0230 0.0046 0.0156 0.0031 0.0054 0.0105 0.0110 0.0015 0.0072 0.0048 0.0107 0.0094 R
6 0.1192 0.1089 0.0623 0.0494 0.0264 0.0081 0.0104 0.0045 0.0014 0.0038 0.0013 0.0089 0.0057 0.0027 0.0051 0.0062 R
|
Soybean Database
- Description: Predict problems with soybean crops from crop data.
- Type: Multi-Class Classification
- Dimensions: 683 instances, 26 attributes
- Inputs: Integer (Nominal)
- Output: Categorical, 19 class labels
- UCI Machine Learning Repository: Description
|
1
2
3
4
5
|
# Soybean Database
data(Soybean)
dim(Soybean)
levels(Soybean$Class)
head(Soybean)
|
You will see:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
Class date plant.stand precip temp hail crop.hist area.dam sever seed.tmt germ plant.growth leaves leaf.halo leaf.marg leaf.size leaf.shread
1 diaporthe-stem-canker 6 0 2 1 0 1 1 1 0 0 1 1 0 2 2 0
2 diaporthe-stem-canker 4 0 2 1 0 2 0 2 1 1 1 1 0 2 2 0
3 diaporthe-stem-canker 3 0 2 1 0 1 0 2 1 2 1 1 0 2 2 0
4 diaporthe-stem-canker 3 0 2 1 0 1 0 2 0 1 1 1 0 2 2 0
5 diaporthe-stem-canker 6 0 2 1 0 2 0 1 0 2 1 1 0 2 2 0
6 diaporthe-stem-canker 5 0 2 1 0 3 0 1 0 1 1 1 0 2 2 0
leaf.malf leaf.mild stem lodging stem.cankers canker.lesion fruiting.bodies ext.decay mycelium int.discolor sclerotia fruit.pods fruit.spots seed mold.growth
1 0 0 1 1 3 1 1 1 0 0 0 0 4 0 0
2 0 0 1 0 3 1 1 1 0 0 0 0 4 0 0
3 0 0 1 0 3 0 1 1 0 0 0 0 4 0 0
4 0 0 1 0 3 0 1 1 0 0 0 0 4 0 0
5 0 0 1 0 3 1 1 1 0 0 0 0 4 0 0
6 0 0 1 0 3 0 1 1 0 0 0 0 4 0 0
seed.discolor seed.size shriveling roots
1 0 0 0 0
2 0 0 0 0
3 0 0 0 0
4 0 0 0 0
5 0 0 0 0
6 0 0 0 0
|
Library: AppliedPredictiveModeling
Abalone Dataset
Photo by MAURO CATEB, some rights reserved.
Many books that use R also include their own R library that provides all of the code and datasets used in the book.
The excellent book Applied Predictive Modeling has its own library called AppliedPredictiveModeling.
If not installed, you can install this library as follows:
|
1
|
install.packages("AppliedPredictiveModeling")
|
You can load the library as follows:
|
1
2
|
# load the library
library(AppliedPredictiveModeling)
|
To see a list of the datasets available in this library, you can type:
|
1
2
|
# list the contents of the library
library(help = "AppliedPredictiveModeling")
|
One highlight datasets from this library that you could use is:
Abalone Data
- Description: Predict abalone age from abalone measurement data.
- Type: Regression or Classification
- Dimensions: 4177 instances, 9 attributes
- Inputs: Numerical and categorical
- Output: Integer
- UCI Machine Learning Repository: Description
|
1
2
3
4
|
# Abalone Data
data(abalone)
dim(abalone)
head(abalone)
|
You will see:
|
1
2
3
4
5
6
7
|
Type LongestShell Diameter Height WholeWeight ShuckedWeight VisceraWeight ShellWeight Rings
1 M 0.455 0.365 0.095 0.5140 0.2245 0.1010 0.150 15
2 M 0.350 0.265 0.090 0.2255 0.0995 0.0485 0.070 7
3 F 0.530 0.420 0.135 0.6770 0.2565 0.1415 0.210 9
4 M 0.440 0.365 0.125 0.5160 0.2155 0.1140 0.155 10
5 I 0.330 0.255 0.080 0.2050 0.0895 0.0395 0.055 7
6 I 0.425 0.300 0.095 0.3515 0.1410 0.0775 0.120 8
|
Summary
In this post you discovered that you do not need to collect or load your own data in order to practice machine learning in R.
You learned about 3 different libraries that provide sample machine learning datasets that you can use:
- datasets library
- mlbench library
- AppliedPredictiveModeling library
You also discovered 10 specific standard machine learning datasets that you can use to practice classification and regression machine learning techniques.
- Iris flowers datasets (multi-class classification)
- Longley’s Economic Regression Data (regression)
- Boston Housing Data (regression)
- Wisconsin Breast Cancer Database (binary classification)
- Glass Identification Database (multi-class classification)
- Johns Hopkins University Ionosphere database (binary classification)
- Pima Indians Diabetes Database (binary classification)
- Sonar, Mines vs. Rocks (binary classification)
- Soybean Database (multi-class classification)
- Abalone Data (regression or classification)
Next Step
Did you try out these recipes?
- Start your R interactive environment.
- Type or copy-and-paste the recipes above and try them out.
- Use the built-in help in R to learn more about the functions used.
Do you have a question. Ask it in the comments and I will do my best to answer it.